
Data cleaning, blending, and transforming are crucial to any data analyst’s career. As data analysts, we often need to work with data collected from different sources. Different organizations have different ways of storing data; even the data operators in the same organization might initially input data differently if there is no standard practice. So, the data team usually runs ETL processes to prepare the data in the required format.
“…..What comes down to are ease of learning and time of implementation.”
There are different tools to do this. No code tools such as Alteryx and Knime or tools where you need to write code such as Python, R, etc. No matter which of these tools you use, you can design comprehensive solutions to meet the requirements. What comes down to are ease of learning and time of implementation.
I ran the data cleaning process using Python and Alteryx on the same data set to see how fast I could clean the data. For this, I chose a data cleaning challenge from the Alteryx community challenge and did the cleaning in both Alteryx and Python. The data is about countries using nuclear reactors to generate electricity and how much of their grid relies on nuclear power.
Now, cleaning with Alteryx was pretty fast. The data was divided into two files, and the cleaning process was similar for both. Once I figured out how to clean the first file, with minor tweaking, I was able to clean out the second file, too. The first task was to check the errors in data, which was quickly done with a browse node in Alteryx. Once I had an idea about the possible errors I could find in the dataset, I could decide on the steps I would take to clean the data. The process steps were to remove null data, select relevant columns, name them correctly, and then select the row range of valid data.
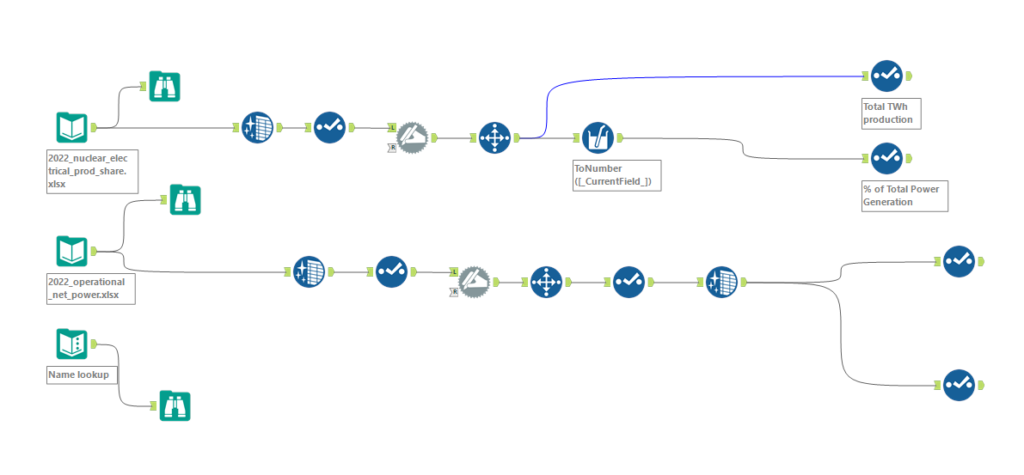
But what it is like to clean same data in python?
I decided to try to do the same cleaning in Python. Although I understood the data by now, I treated it as new and followed the usual steps. I used the VS code with the jupyter notebook extension. First, I loaded the data into the data frame. Then, I used .info() to check for data type errors.
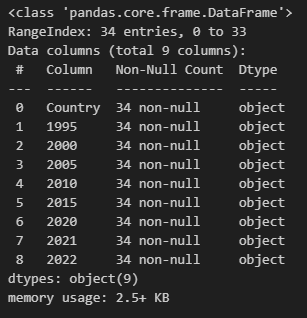
Since the amount of data was limited, I could see columns with Null or NA values. But if there was lots of data, a good step would be to check the data with .unique().describe(). You can filter out these Null or NA values if they are much lower compared to total data points. Or, if you decide to impute the values, you can use .fillna() to impute the value as per requirement. In this case, by consulting another file, I realized that the column had NA cause there was no power generation for that particular period using a nuclear reactor. So, I imputed these values to be 0. But before that, I needed to fix each column’s names and data types. After that, I removed unnecessary rows and columns and output the data into four files.
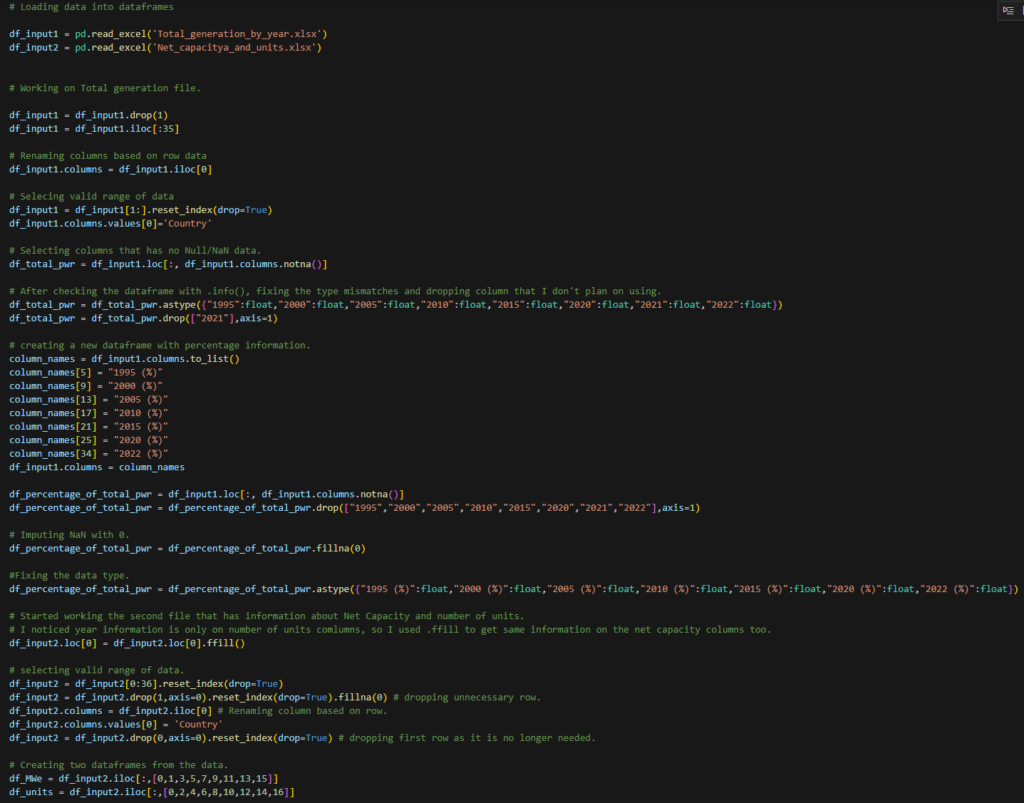
While performing data cleaning tasks using two different tools, Python and Alteryx, Alteryx was far more easier. Overall, Alteryx took way less time than it took me in Python. Considering how expensive Alteryx is, that makes sense. I am not trying to sell Alteryx, but I know for sure which one I would choose if I had an option between these two.